
ELK安装配置
ELK常见架构
Elasticsearch + Logstash + Kibana
这是一种最简单的架构。这种架构,通过logstash收集日志,Elasticsearch分析日志,然后在Kibana(web界面)中展示。这种架构虽然是官网介绍里的方式,但是往往在生产中很少使用。
Elasticsearch + Logstash + filebeat + Kibana
与上一种架构相比,这种架构增加了一个filebeat模块。filebeat是一个轻量的日志收集代理,用来部署在客户端,优势是消耗非常少的资源(较logstash), 所以生产中,往往会采取这种架构方式,但是这种架构有一个缺点,当logstash出现故障, 会造成日志的丢失。
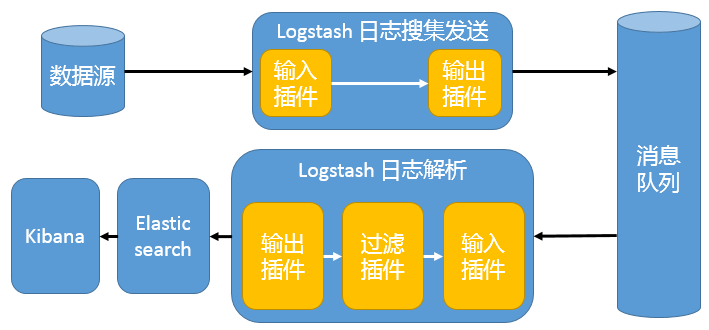
Elasticsearch + Logstash + filebeat + redis(也可以是其他中间件,比如kafka) + Kibana
这种架构是上面那个架构的完善版,通过增加中间件,来避免数据的丢失。当Logstash出现故障,日志还是存在中间件中,当Logstash再次启动,则会读取中间件中积压的日志。
filebeat安装部署
简介
Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者logstarsh、redis中存放。
工作原理
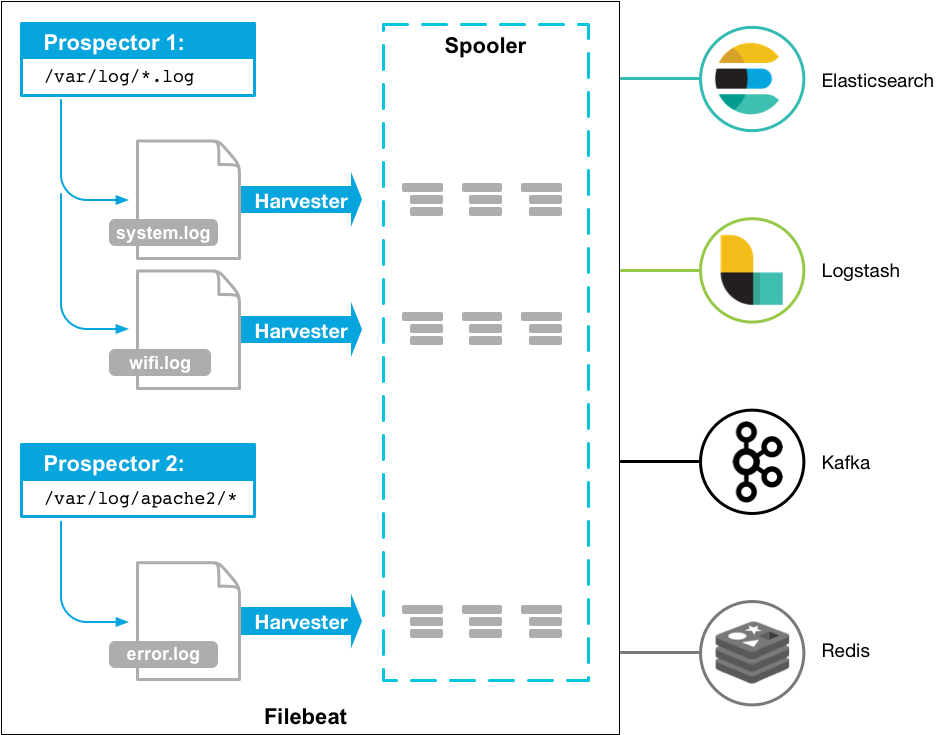
filebeat由2个主要组件构成:prospector和harvesters。这两类组件一起协同完成Filebeat的工作,从指定文件中把数据读取出来,然后发送事件数据到配置的output中。
harvesters:主要负责进行单个文件的内容收集;在运行过程中,每一个Harvester会对一个文件逐行进行内容读取,并且把读写到的内容发送到配置的output中。
Prospector负责管理Harvsters,并且找到所有需要进行读取的数据源。如果input type配置的是log类,Prospector将会去配置度路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。每个Prospector都运行在自己的Go routine里。
当你开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
下载
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.2.2-x86_64.rpm
sudo rpm -vi filebeat-5.2.2-x86_64.rpm配置
#=========================== Filebeat prospectors =============================
#filebeat.prospectors模块用来指定日志文件的来源。
filebeat.prospectors:
- input_type: log #input_type 指定日志类型,在这里是log, 应该也可以是json
enabled: true
paths: #paths指定日志文件路径。
- /root/myapp/tomcat/tomcat8/logs/*.log
#================================ redis =====================================
output.redis:
hosts: ["152.136.233.203:6379"]
password: "redis"
datatype: list
key: "tomcat-log"
db: 1
#document_type:这个字段是用来给日志打标记的。
#fields: 也是打标记,主要为了后面日志分析查找的方便,存储的时候也会根据fields分类存储,相同fields的数据存在同一个redis key中
#fields_under_root: 如果该选项设置为true, 则该fields会存储在top-level中。
#tail_files: 这个选项如果设置为true,则读取日志文件的新内容,而忽略原有的内容,一般要设置为true启动
systemctl start filebeat问题
filebeat怎么设置从头开始读取
找到registry文件的位置,如果没有单独配置那么文件路径为
/var/lib/filebeat/registry,不在也没关心,可以直接find命令查找find / -name registry关闭filebeat –> 删掉registry文件 –> 启动filebeat
Filebeat插件启动失败,不能直接查找报错原因
老是在filebeat启动的这一步骤上出错,但是由于filebeat是由systemd启动的,因此原因也经常查不清楚,因此并不能直观的查出错误在哪里,所以今天教给大家两个寻找错误的根源的方法:
直接使用filebeat的启动方法,而不使用systemctl start filebeat来启动。比如:
/usr/share/filebeat/bin/filebeat -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat
logstash 安装配置
下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.2.2.tar.gz
tar xf logstash-5.2.0.tar.gz -C /opt/app/配置
mkdir -p /data/ls-data #创建/data/ls-data目录,用于logstash数据的存放
chown -R logstash:logstash /data/ls-data #修改该目录的拥有者为logstash
mkdir -p /log/ls-log #创建/data/ls-log目录,用于logstash日志的存放
chown -R logstash:logstash /log/ls-log #修改该目录的拥有者为logstash创建配置文件
mkdir -p /config/logstash/config.d
vim logstash.confinput {
redis {
host => "localhost"
port => "6379"
db => "1"
data_type => "list"
key => "tomcat-log"
codec => plain {
charset => "UTF-8"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "tomcat-log"
}
stdout { codec => rubydebug }
}input是redis, 需要指定redis的host 和port以及db,还要指明数据的类型,list表示这是一个redis的list对象。key指明redis中的key名称。
output 是elasticsearch, hosts指明elasticsearch的ip和端口,index指明这个日志存在elasticsearch中的索引名称。
修改配置文件(/opt/logstash-5.2.2/config/logstash.yml)
# 设置数据的存储路径为/data/ls-data
path.data: /data/ls-data
# 设置管道配置文件路径为/etc/logstash/conf.d
path.config: /etc/logstash/conf.d
# 设置日志文件的存储路径为/log/ls-log
path.logs: /log/ls-log测试logstash
./logstash -f /config/logstash/config.d/logstash.conf --config.test_and_exit
#--config.test_and_exit表示,检查测试创建的logstash.conf配置文件,是否有问题,如果没有问题,执行之后,显示Configuration OK 证明配置成功!启动
nohup /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash.conf &elasticsearch安装
下载
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.tar.gz
tar -xvf elasticsearch-5.2.2.tar.gz -C /opt/app/配置
mkdir -p /data/es-data #创建/data/es-data目录,用于elasticsearch数据的存放
chown -R elasticsearch:elasticsearch /data/es-data #修改该目录的拥有者为elasticsearch
mkdir -p /log/es-log #创建/data/es-log目录,用于elasticsearch日志的存放
chown -R elasticsearch:elasticsearch /log/es-log #修改该目录的拥有者为elasticsearch修改配置文件 (/opt/elasticsearch-5.2.2/config/elasticsearch.yml)
#设置data存放的路径为/data/es-data
path.data: /data/es-data
#设置logs日志的路径为/log/es-log
path.logs: /log/es-log
#设置内存不使用交换分区
bootstrap.memory_lock: false
#配置了bootstrap.memory_lock为true时反而会引发9200不会被监听,原因不明
#设置允许所有ip可以连接该elasticsearch
network.host: 0.0.0.0
#开启监听的端口为9200
http.port: 9200
#增加新的参数,为了让elasticsearch-head插件可以访问es (5.x版本,如果没有可以自己手动加)
http.cors.enabled: true
http.cors.allow-origin: "*"启动
注意,如果你使用root用户启动elasticsearch,就会报错,启动失败,这是因为elasticsearch不允许用root用户启动。可以创建一个用户,用来启动elasticsearch
groupadd elasticsearch #添加组
useradd -g elasticsearch elasticsearch #添加用户
chown -R elasticsearch:elasticsearch /opt/app/elasticsearch-5.2.2/ #设置权限
/opt/app/elasticsearch-5.2.2/bin/elasticsearch -d #启动,后台运行kibana安装配置
安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.2.2-linux-x86_64.tar.gz
tar -xzf kibana-5.2.2-linux-x86_64.tar.gz -C /opt/app/配置(/opt/app/kibana-5.2.2-linux-x86_64/config/kibana.yml)
server.host: "0.0.0.0" #指明服务运行的地址
elasticsearch.url: "http://localhost:9200" #指明elasticsearch运行的地址和端口
kibana.index: ".kibana" #指明kibana使用的索引,这个是自定义的。启动
/opt/app/kibana-5.2.2-linux-x86_64/bin/kibana参考
https://www.jianshu.com/p/e7362ccfe7e3
http://www.justdojava.com/2019/08/11/elk-install/